How we built a SimOps platform that runs twice as fast for half the cost of a vanilla deployment in Kubernetes. A compound advantage our customers inherit on day one.
Introduction
As physical AI products grow more complex and safety-critical, the need for large-scale offline testing such as simulation and “replay” testing becomes unavoidable. The decade and a half and billions of dollars spent in the autonomous vehicles industry — including by most of us! — demonstrated this the hard and expensive way. Simulation is no longer a nice-to-have, but a necessity as we have previously discussed.
Many robotics teams, rightly, start with field testing and local simulation setups—for example, powerful desktops or laptops running Gazebo or other simulation engines, often containerized in Docker. Field testing, in particular, works great in the early days. It takes place directly in the robot’s intended operational environment, giving teams fast and tangible feedback from the real world. It helps surface edge cases that simulations might miss, and makes it easy to build intuition around robot behavior and failure modes.
Local setups also offer significant advantages at this stage: developers benefit from low latency, direct environment control, and minimal infrastructure complexity as a proof of concept is developed. However, as the team grows and the competency of the robot and its operational design domain expands, local resources start to strain—and the cracks begin to show.
The cloud, as always, promises a way out: massive parallelism, on-demand compute, and centralized environments. Moving simulations into the cloud isn’t just a lift-and-shift. It introduces its own set of challenges. It is our hard-won and validated belief that these challenges are uniquely difficult and often drastically underestimated.
Enter SimOps: the practice of operationalizing simulation pipelines, infrastructure, and tooling to make robotics simulation testing work at scale. Just as MLOps transformed machine learning workflows, SimOps is the next step for robotics testing.
In this blog, we break down the toughest challenges in SimOps and how ReSim delivers it as a fast, efficient, reliable service, so your team can stay laser-focused on delivering real-world robotics.

The challenges of building a cloud SimOps platform
When moving robotics testing to the cloud, teams face hurdles in orchestration, observability, cost, and developer experience. On top of that, physical AI testing is inherently demanding — it requires heavy compute (often GPUs), produces large artifacts (MCAPs, images, videos), and overwhelms teams with data, edge cases, and unclear result attribution.
At first glance, cloud services like AWS Batch or Kubernetes look like they should be enough: you get orchestration, autoscaling, and managed infrastructure. And, yes: you can run your jobs.
But simulation at scale in robotics is not a generic workload. It raises a cascade of questions:
- How do you trigger a test suite — from your laptop, CI, or both?
- How do you know when tests are done — and what passed or failed?
- What happens when one test fails out of a hundred?
- What kind of compute do these jobs actually run on?
- If you’ve just pushed a change, how do you re-test and compare it?
- And where exactly do you find the logs?
- How much did this cost me?
These are not edge cases: they’re the daily, practical concerns of any robotics team trying to scale simulation beyond a single machine.
Furthermore, SimOps workflows follow recurring patterns that reveal huge opportunities for optimization. Tailoring infrastructure to these patterns can unlock 10x improvements in speed, cost-efficiency, and developer velocity if you know where to look, and have the time to invest.
Unfortunately, most platforms offer a poor developer experience for robotics engineers unfamiliar with tools like kubectl or the AWS CLI. SimOps requires a higher-level interface — one that centers on tasks, test suites, and results, not pods, containers, and logs.
In the sections below, we’ll walk through the six biggest reasons SimOps is harder than it looks and how we’ve solved each one.
Six Real Problems in SimOps (and How ReSim Solves Them)
Each of these challenges represents an opportunity to drastically improve throughput, reliability, or developer productivity — if you have the time and team to engineer the solution.
1. Orchestration isn’t just “running jobs”
Problem
Naively running each test as an isolated job (as Batch and K8s do) leads to cold GPU starts, repeated image pulls, and wasted spin-up time — especially during CI/CD-driven bursts. The default autoscalers can’t keep up.
Our Solution
- Built a custom scheduler, tailored to the workflows required in robotics testing, that amortizes setup costs by running many tests per worker, not one-per-job.
- Flexibility for customers on priority and parallelism on jobs
- Optimized cluster scaling logic tuned for burst workloads.
- Nodes are reused intelligently, avoiding repeated GPU provisioning and image pulls.
Benefit
We reduce job latency and total cost per test, even under CI-driven spikes. Even with massive Docker images, most test suites on ReSim go from submission to execution in under 2 minutes. Low-priority overnight tests run up to 30% cheaper per test than smaller, high-priority ones.
2. Retries, Failures, and Smart Scheduling Are Non-Trivial
Problem
Once you’re running thousands of tests, failures happen: flaky simulations, missing images, misconfigured inputs. Most infrastructure can’t distinguish between:
- Retries that should happen automatically (e.g. an unhealthy node).
- Failures that need human attention (e.g. a segmentation fault in your sim).
Our Solution
- Built-in failure classification: we distinguish between infrastructure errors (e.g., timeouts, node faults), build errors, and sim-level flakiness.
- Any underlying infrastructure errors are retried transparently and flagged clearly for investigation by ReSim when they can’t be.
- Customers can provide unique error codes for their systems that are surfaced in the API and UI.
- Individual failing tests can be rerun to avoid having to redo the entire batch.
- Logs and outcome metadata are organised and presented through our API and UI.
Benefit
Engineers spend less time chasing logs and more time fixing real issues. ReSim avoids wasted retries and highlights what actually needs attention.
3. Image Handling, GPU Setup, and Input Data Are Fragile Bottlenecks
Problem
Robotics testing involves huge amounts of data that needs to be handled carefully in the cloud:.
- Image pulls are slow, especially with the large Docker images typically needed for simulation. Tools like the NVIDIA GPU Operator solve driver provisioning with nodes using these images, but add 2+ minutes to node startup time. Across thousands of tests, that adds up fast.
- Test input data is typically large files such as MCAPs, maps, world files. Pulling them from cloud object storage adds latency. Baking them into images inflates image size. Caching is key - and hard.
Our Solution
- Bake common layers (ROS, cuda, isaac-sim etc) into custom AMIs to skip cold starts.
- Use job-type–specific node pools with pre-installed NVIDIA drivers and other dependencies.
- Artifact and experience caching with fingerprinting and incremental snapshotting/restoration to avoid wasteful transfers.
Benefit
Consistent startup times and lower per-job overhead. Instead of copying a 10GB replay MCAP from S3 every time that test is run, ReSim copies it once, saving hours of compute time over the useful lifetime of that test.
4. Developer Experience Is Often an Afterthought
Problem
For robotics engineers, familiar with local development, the cloud is a daunting place:
- Remote logs are buried in cloud dashboards or CLI tools, leaving robotics engineers to trawl Cloudwatch.
- Debugging a failure means pulling logs, reconstructing environments, and hoping it reproduces locally.
- Hardware-in-the-Loop and field testing gets evaluated using a completely different tool set, reducing cross-mode fidelity.
Our Solution
- Debug mode: drop in to a copy of your container in the cloud to interact - inspect the filesystem, run test commands and work out what’s wrong more quickly than making changes and running tests repeatedly.
- Unified CLI and UI access to logs, artifacts, and metrics.
- Seamlessly re-run tests and compare tests across different branches via API and UI.
- Hardware-in-the-Loop and field tests can be orchestrated (HiL) or processed (field tests) and visualized using the same platform.
Benefit
Faster iteration loops, higher trust in the system, and lower activation energy to debug.
5. Costs are spiky, invisible, and easy to get wrong
Problem
Simulation costs are spiky and unpredictable. A single rogue job can drain your cloud budget in hours. Most teams have no way to know until it’s too late. Significant infrastructure engineering time is needed just to keep costs predictable.
Our Solution
- Predictive binpacking: smarter scheduling based on historical task durations.
- Per-suite and per-job cost tracking, with budget alerts.
- Guarantees of right-sized nodes for workloads.
- Flexible lifecycle policies for output data storage, so that the cost of keeping huge volumes of outdated robotics data in the cloud doesn't spiral out of control.
Benefit
Predictable costs with fewer billing surprises: A platform that works with your budget, not against it.
6. Platform-as-a-service, not another project
Problem
Infrastructure tax is real. Every hour spent managing simulation infrastructure is an hour not spent improving your robot.
Our Solution
- Simulation-as-a-service with end-to-end orchestration, artifact handling, and metrics.
- Hosted control plane, no k8s config needed.
- Customer teams plug into our API and focus on testing, not infrastructure. Familiar interface for local testing of single containers and Compose files for multi-container orchestration.
Benefit
Our customers save time, reduce risk, and move faster on what matters to them: building better robotics systems. Let us worry about the infrastructure and its maintenance.
Conclusion
Simulation is foundational to building safe, robust robotics systems. But to make it scale, you need more than just a simulator, you need a platform.
Building that platform is not a side project. It’s a full-stack product problem that most teams don’t plan for, and that robotics orgs shouldn’t build from scratch.
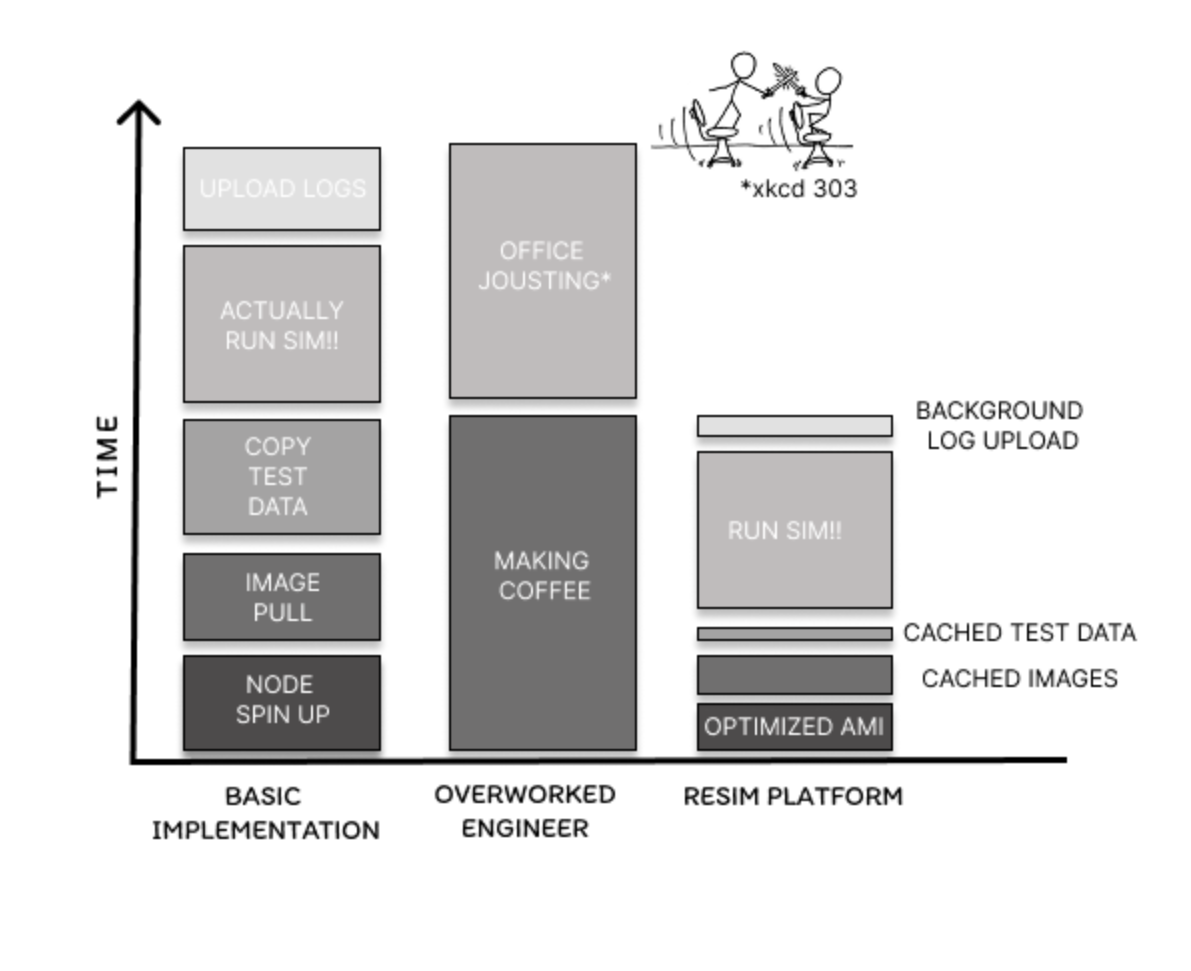
ReSim has invested over 30 person-years building and iterating on a purpose-built SimOps platform and the results speak for themselves:
Our current system runs twice as fast for half the cost of our earliest MVP. And our customers inherit that compound advantage on day one.
We handle the orchestration, debugging UX, cost controls, and reproducibility, so you can stay focused on the hard stuff:
- Creating a library of test suites that cover their domain
- Developing metrics to evaluate their system’s performance
- And most importantly: accelerating the development of their core technology.
Let us handle the SimOps.